




Opportunity amid Deep Panic
The AI revolution likely has decades to play out. However, we appear to be at a turning point. Open, small and smart versus closed, big and not so smart.

I have waited a few days since the beginning of the market panic over the release of the Chinese AI model DeepSeek, by a team led by quant-guru Liang Wenfeng.

Nerd is a term of endearment to me. I have a theoretical physics background, as well as a few decades in quantitative finance. When I heard the story of Liang Wenfeng, and his hedge-fund spin-out DeepSeek, my prejudice was all positive.

It pays to wait a few days when news breaks, as this story is all about prejudice.
Which do you think Wall Street would think was the hedge fund guy?
Would it be A: the slender nerd speaking to the Chinese Premier; or B: the random Chinese fellow named Liang Wenfeng the Western media latched onto?
It was the first one, the nerdy one, the one who did not look like a hedge-fund guy.
I trained as a mathematical physicist, whose teachers extolled in me the virtues of reading the original literature and learning from the greats in their own words.
I have a book on my shelf on Harmonic Analysis by this Chinese farm boy.

His name is Hua Luogeng, or Hua Loo-Keng, or on my AMS translation Loo-Keng Hua.
He was famous in mathematics circles.
The U.S. National Academy of Sciences did a special biography on him when he died.
Here is another farm boy who made good in mathematics.

Carl Friedrich Gauss was another farm boy of modest means who shot to the top. He was so good many of his results were only published after his death.
Gauss discovered a way to do Fourier Transforms quickly in 1805, using only limited algebra, that was not discovered subsequently until Cooley and Tukey rediscovered the same algorithm in 1965. Genius is like that. Ahead of its time.
In the world of U.S. Exceptionalism, we are supposed to believe that intelligence can only be secured by Silicon Valley billionaires waving wads of other people’s money.
The prejudice shown by Silicon Valley is a massive investment opportunity.
The belief was that only a firm with huge resources could ever compete.
Sam Altman, co-founder of U.S. AI firm OpenAI famously said:
It's totally hopeless to compete with us.
Then along came DeepSeek and did exactly that.
What did DeepSeek do, exactly, and why does it matter?
To understand that we need a whirlwind history of Artificial Intelligence.
A short history of Artificial Intelligence
There are many sources, a good leisurely one is the Computer History Museum.
The one above is ten years old, which is helpful.
Then we have context of what happened before Silicon Valley “did everything”.
The thinker I will pick out is Alan Turing, who developed the Turing Test.

Alan Turing framed his test of intelligence as an input-output comparison.
We consider humans to be intelligent, and so we can test that by asking them a series of questions. Marking answers, we might decide some humans are more intelligent.
Now do the same with a machine by giving them a test.
If the machine gives similar answers to similar questions, and these are judged to be correct answers, in the same sense we test humans, then the machine is intelligent.
It is a simple comparison test of input versus output quality, speed and accuracy.
Just like in school, we frame tests, mark tests and score intelligence.
Passing this test does not say anything about the experience of intelligence. It does not address questions like consciousness, humanity, or a sense of self.
For practical purposes, this does not matter if your purpose is to improve productivity at appropriate tasks. Some say it is enough to do this and there is no more to it.
Perhaps. Perhaps not.
What matters today, is advances in computer algorithms, relating to how you train a neural network to recognize, organize and generate patterns in data.
This trend began with work on artificial brains, pursuing the idea that mimicry of the structure of the brain could help us decode how we “do intelligence”. This revolved around the study of neurons, how they connect to each other, and learning.
This started in earnest with Frank Rosenblatt in 1957, and his artificial neuron, which he called a perceptron, and a custom-built computer that linked these together.
Progress in this direction proceeded by fits and starts.
In 1969, Marvin Minsky and Seymour Papert wrote a book called Perceptrons.

This book is both famous, and infamous.
It is famous because it is a good book.
It is infamous because it contained a mathematical proof that you could not possibly achieve general data mimicry, matching input pattern to output pattern, using only a single layer of artificial neurons. Your networks needed to be more complicated.
It should not be surprising that the field of artificial intelligence meandered. Just like the natural cousin disciplines of mathematics, philosophy, and psychology, there are many possible perspectives on intelligence, and many ways to skin a Hegelian cat.

I do not think the human significance of meta-intelligence, the spirit, will ever change.
What matters for our all-too-brief pretend history of Artificial Intelligence is this:
Perceptrons proved one-layer neural networks are bad, but two layers will do.
In deference to my dad, the theologian, I am saying intelligence is not everything.
Closing the Turing Circle
Recall that Alan Turing framed artificial intelligence as machine mimicry. You would count as intelligent if you gave similar outputs for similar inputs to those of humans.
Remember I mentioned that Perceptrons, the book, proved that a single layer neural network cannot mimic general relationships of an input to an output.
In short, you are going to need many neurons, that are connected in layers, and you are going to have to figure out how to represent a variety of inputs and outputs.
You also need to learn how to train a network, and a bunch of other things besides.
There is a huge amount of work that went into this but let me pick out some history that highlights the hop, skip, and jump that got us this far, so very slowly.
The hop
Mathematics is very useful when it can guide a big search.
Why look everywhere if the mathematics says you only need to look here?
Perceptrons said that one-layer neural networks will not do.
One important step forward, was an innovation by John J. Hopfield, an American physicist who was at Princeton University at the time, in 1982.
He built on early ideas for recurrent neural networks, where neurons are connected each to one another, so that there is a feedback effect. The mathematics of this is related to some optimization problems in physics, where the natural goal of the system is to find an equilibrium state of lowest energy.
The brain is a physical system, so thinking of learning in this way, as finding the best fit between an input and output pattern, is fairly natural. Water will find the lowest point on a hilly landscape and just flows there. Why not the neural connections.
The hop, as represented by Hopfield’s recurrent networks won him recognition in the 2024 award of the Nobel Prize for Physics. This was the first ever Nobel Prize for AI.
Related ideas, namely the Boltzmann machine, represented a different way of thinking about network connectivity, that also had a connection with energy in physics.
The creator of this network, Geoffrey Hinton, shared the 2024 Nobel Prize for Physics for his invention of these networks, and their application to image classification.
The skip
The two ideas of using differently connected networks, and an optimization process akin to energy minimization to capture the idea of learning, created a boom in the neural computing industry in the 1980s. However, this ran out of steam due to the problem that large and deep networks could prove to be unstable.
The energy hill on which the water was flowing has too many minor hills and valleys for the water to settle down properly. The slope could prove to be too shallow.
These are mathematical algorithm issues that plagued the field of deep learning, as multiple layer networks were called, during the 1990s and early 2000s. During that period many folks in academic circles abandoned neural network research.
The French researcher Yann LeCun made major steps forward in 1989, and during the 1990s, developing practical methods to train multi-layer deep neural networks.
This led to a famous paper and system for handwriting recognition of Zip codes.
These were great steps forward but extending the ideas still proved difficult. There were products like the Apple Newton, but the technology was still immature.

For doing effective AI, the available computer power also matters.
The jump
The real jump forward came around 2012, when an AI entry in the ImageNet image recognition and classification contest aced all other competitors. This is like a very simple Turing Test for robot vision, where they are asked to label images.
Cat, dog, horse, hippopotamus on a jet-ski…
The concept is very simple, but achieving human level accuracy across thousands or millions of images proved very difficult. In principle, AI seemed like the way. All you would need to do was to “train” your system on a vast library of labelled data, and away you would go showing that machine new images to label.
Doing this was hard, until two things happened.
Somebody figured out how to apply Graphics Processing Units (GPU), the video gaming cards now made famous by NVIDIA, to training neural networks.
Three University of Toronto researchers, Alex Krizhevsky, Ilya Sulskever, and the same Geoffrey Hinton who won the 2024 Nobel Prize for Physics, used an NVIDIA GTX 580 graphics card, to develop and train their winning AlexNet competition entry.
This kicked off the modern Deep Learning boom.
There are far too many innovations to do justice here, so I will mention two that have a relationship with what is going on with DeepSeek, and efforts to surpass it.
Arguably, the most significant engineering leap forward was the Google Transformer Architecture for joining an input deep neural network to an output neural network.
This involves breaking the problem into two parts. You train a neural network to classify and organize the world of inputs. Then you do the same on outputs.
You join them in the middle in a general, and simple way, that draws on the energy minimization ideas of Hopfield and Hinton. There is more to it than that, however engineering is an appropriate label for the utility of this idea.
Want to translate English to French, and or back again.
Train one neural network to abstract the patterns of English, and another to do that with French, and then join them at the abstract layer in the middle.
This way you can transform English to French and back again.
Equally, you could transform images to captions or captions to images.
There is massive engineering in making this simplistic description of the key idea work well and do so at scale across a huge variety of inputs and outputs.
However, once you grasp the idea that a neural network can be trained to recognize, reproduce, and even generate the patterns inherent in a class of inputs, you can turn that around, via the transformer, and join one crazy input class to an output class.
This is true engineering of the best kind, since you now have a recipe for progress.
Wham, blam, you have neural nets doing all kinds of things.
The second big jump is something called a foundation model.
This is the name given to a general-purpose model that was simply thrown a huge amount of data and not told what class of pattern to look for.
You would throw it a dump of the internet, through say the Common Crawl, and it would go find all the patterns in such data. Code, poetry, facts, images, the works.
Foundation model training is looking much more like how humans learn.
We are exposed to our own sensory stream, and organized information like textbooks, or Wikipedia, and off we go learning whatever we might from a mass of data.
Look at enough data, and emergent properties appear.
The model was not told anything about the computer language Python, but it read the Web and learned how to code in that language. Not perfectly, but pretty well.
You know the rest, because you have lived through it.
Foundation models are remarkably effective.
Is data all that you need?
Put aside all of the philosophical questions a modern Hegel might pose.
The bottom line of the NVDIA GPU focused, and data centre focused, Foundation Model AI boom, is something called a scaling law. This is the empirical observation that if you throw more data, at a larger computer, to train larger models you win.
The paper Deep Learning Scaling is Predictable, Empirically, from 2017, started a race among AI developers to build the biggest deep learning computer, with the largest possible training data set, and the biggest ever model, to win the race.
There is no real end to such a race, other than running out of data, or power to run the computer, or water to cool it, or money to pay for everything involved.
Superficially, it looks like data, computing, and money is all you need.
There are four parameters that describe learning: model size, dataset size, training cost, and the post-error training rate, and empirical relations that are scaling laws.
It really looks like the biggest and best funded team with the most data will win the race simply because that is what the scaling law says.
What about intelligence?
Follow the siren-song of the Venture Capitalist and all you need is money and data.
Throw a huge amount of data at the machine and you will discover physics!

I purposefully chose this example to refer back to my introduction on mathematics.
The reason that lazy people like me study physics and mathematics is because we do not need a big computer, massive funding, or huge amounts of data.
Albert Einstein was a creative spirit who believed that Nature chose simple and beautiful laws that were expressed in the form of beautiful mathematics.
On his own admission, he was a terrible student.
Einstein believed that imagination was more important than knowledge.
Without reading every mathematics and physics textbook of his time, he read enough about Tensor Calculus, and had enough good friends to quiz about it, that he figured out a set of field equations that have proven correct to this day.
There was no scaling law involved in this enterprise.
There were plenty of other physicists scribbling equations, but Einstein was the one who found an equation, one that was not written down before, which was right!
Where is the loophole?
The human brain occupies about one liter of volume and uses 60W of power.
You could power, and pay for, a lot of brains with the space, energy, power and dollar budget of a Microsoft data center, as rented out for equity to OpenAI. This poses a simple and cogent question about the nature of intelligence.
How come Einstein could create his field equations without reading the Web?
Superficially, this seems like a nonsense question.
However, I think it relates directly to what DeepSeek claim to have done.
To set the scene you may find this video useful.
It is a good explanation of the model, and shows examples of its chain of thought mode, where it thinks out loud, about the steps and data leading to a conclusion.
We all do this, in the privacy of our minds, and it is instructive.
This is the model adjusting its path, as it goes, by reflecting on what it knows, and what it has learned so far. You can imagine using such a model structure to go get new data whenever that known by the model which is insufficient for the task.
In short, and to trivialize the model, this is active reflection and self-study.
The above video has a diagram outlining the basic training idea.

I will not attempt to be technically accurate in this description. The model is Open Source, meaning you can download the model and supporting code to run.
You can read the full technical report here.
The research community will in full course weigh in with their own judgments of significance and scope for further model improvement and innovation.
I am going to weigh in with my own conclusions from operating a real live brain.
The concept that I would go read the entire Web to learn something seems pretty foolish to me. I would rather use an AI someone else trained that way, and use it, alongside my own intellect, to refine and improve my reasoning.
There is an aspect to intelligence beyond knowledge, and pattern recognition and generation. These are the form and process of appearing intelligent.
True intelligence, in my world, is getting by with what you do know in order to figure out what you don’t know, and perhaps that which nobody yet knows.
This requires intelligent reflection, which we call reasoning.
This is a current thread of AI research, including at the leading firm OpenAI.
The DeepSeek model stacks up well versus other models and uses less resources.
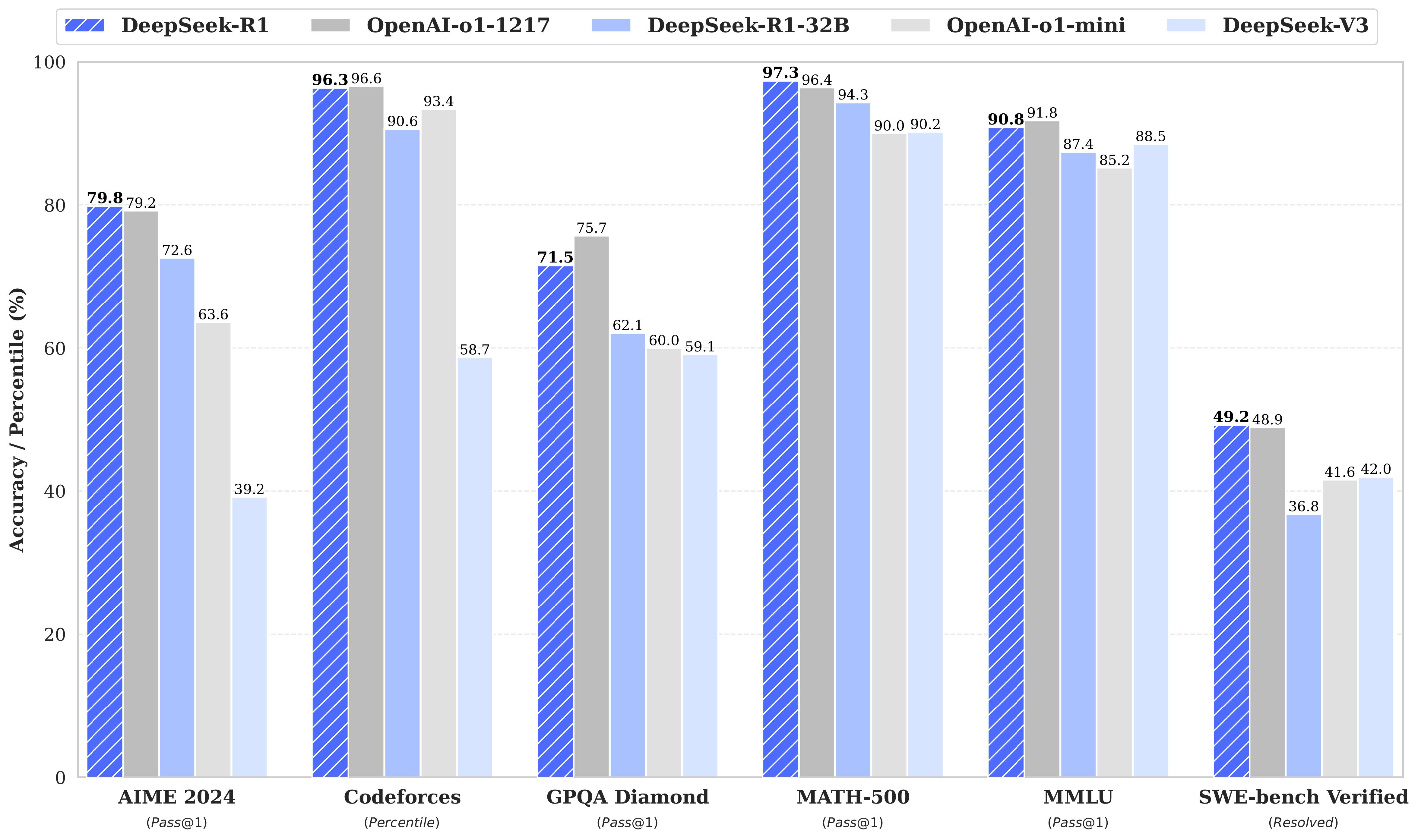
The key ideas involved are several, but the one I focus on for investment purposes is the lower resource usage. Whatever is being done to apply a Chain of Thought (COT) reasoning layer appears to be producing the effect I would expect.
Good mathematicians and physicists do not carry around massive databases.
They substitute thinking, at the test time, for compute and storage at train time. They learn what they need and distill that to a set of principles that distill knowledge.
If you can reason, according to principles, and tests of relevancy for salient facts, then you can compress the required memory, compute, energy and power for intelligence.
Recall what I wrote above:
There are four parameters that control learning: model size, dataset size, training cost, and the post-error training rate, and empirical relations that are scaling laws.
The way to beat the seeming barrier of scaling laws, is to iteratively condense or distill those principles that summarize data seen, so that new data promotes learning.
Trust me when I say this…
If you read one good book on complex numbers, you read them all.
I am purposefully trivializing a beautiful and subtle corner of mathematics.
This is an area where structure rules, and that structure is the learning.
This is not true of learning how to tell a cat from a dog.
However, meta-models that operate at the level of captions can reason out why a Platypus bears some similarity to a duck, some to an otter, but is neither.

Reasoning, on symbols that are assigned to things before us, is a human way to compress and organize what we know so that it is more useful.
Humans have trouble reasoning to great depth, but we have ways to organize what we know to make the task fit within the available computing power we have.
DeepSeek would appear to have used OpenAI model input-output data as one path to learning. This process of one model learning from another is called distillation.
However, it is also a method for reducing the model size with similar performance.
If you believe that scaling laws mean you must have the largest possible computer, and the biggest data set, then you are probably doing AI wrong.
Humans do not do that.
What DeepSeek appears to be doing is something we call thinking.
How can I win a race against those who are bigger and better funded than me?
Thinks…
Aha! I could think a bit about what a scaling law is really saying.
Somewhere, as part of my learning process, I could stop, reflect, and distill what I have learned into a set of principles that capture what I have learned, and move on.
This crude way to describe what just happened, in anthropomorphic terms, recalls an earlier time in AI research when the computers had limited power. This period was called Symbolic Artificial Intelligence. This involves the use of rule sets of premises, alongside computational logic, to solve problems.
This is brittle because a lot of real-world intelligence is analogical.
For instance, a platypus is like both a duck and an otter, but it is neither. Analogical reasoning, combined with logical inference, would explore what attributes a duck would have and which an otter would have to posit properties for a platypus.
It turns out that a platypus lays eggs like a duck but is a mammal like an otter.
In fact, a platypus is a monotreme: an egg laying mammal.
Intelligence is more subtle than simply reading everything and spotting patterns.
There is a reduction phase which is an informational compression.
What DeepSeek portends is a loophole in the scaling laws.
Perhaps to be the smartest you should stop doing dumb things?
Here is my definition of intelligence.
Do not waste time, energy, and money, doing pointless things.
If there is a better way, find it. If someone else finds it, then go use it.
Conclusion
This is a very long and discursive post which is best made free.
I needed to think through what I thought at a meta level
Here is the abstract summary:
Reasoning ability matters to distill and compress knowledge
Iteration in learning can happen at a meta-level of models on models
Knowing how to make meta-learning recurrent is key
In simple terms, smarter models will likely reflect on themselves, pick lint from their own brain, stare at it, throw away the bad lint, and knit a jumper with good lint.
In short, they will be more human not less human.
When they do not know something, they will stop, say so, reflect, think about what precisely is missing, go find that, and then pick up where they left off.
They will not be dumb like present AI.
The effects on companies will be many and varied. I will do another post tomorrow on stock-specific ideas. However, the broad picture is clear:
Open-Source models can be improved by other Open-Source models
Capital spending alone is unlikely to be a predictor of success.
Teams thinking about previous AI trends are likely better placed
In the same way that the Transformer Architecture kicked off a Cambrian Explosion of specialized models, the Foundation Model boom, combined with meta-learning, of models learning from other models, to distill knowledge and rules, is a winner.
DeepSeek is well placed, but so is Meta, Alphabet and OpenAI/Microsoft.
According to the early market reaction Meta is the one folks are backing.
There will be stock-specific discussion tomorrow.
Enjoy the spectacle!


Where do I find the stock-specific discussion?